Cette page présente la taille du corpus et la liste des documents intégrés à ParCoLab.
Taille du corpus
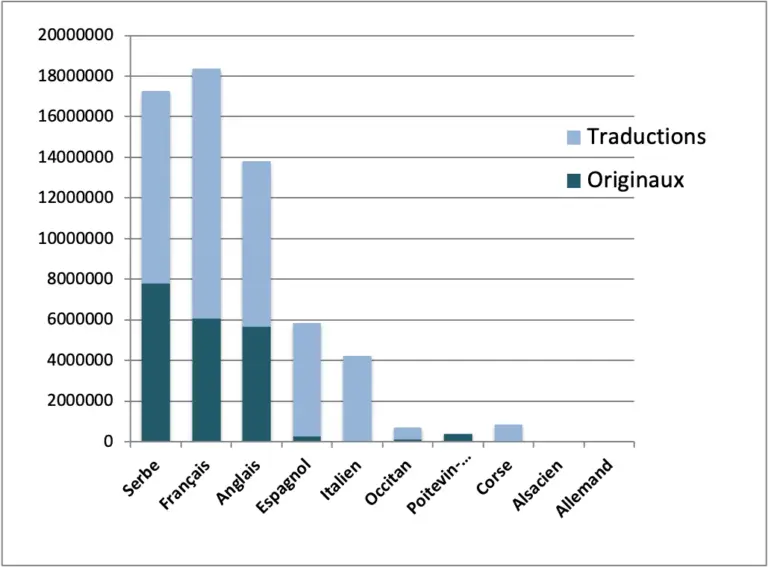
Le corpus parallèle comporte au total 62.000.000 de mots, les quatre langues comprises. Les données récoltées se répartissent comme suit:
Liste des documents intégrés
Le corpus comporte des textes écrits en français, en serbe, en anglais, en espagnol, en italien, en occitan, en corse, en alsacien ou en poitevin-saintongeais et leurs traductions. Vous y trouverez également des textes juridiques et philosophiques, la presse, les transcriptions de films et conférences, etc.