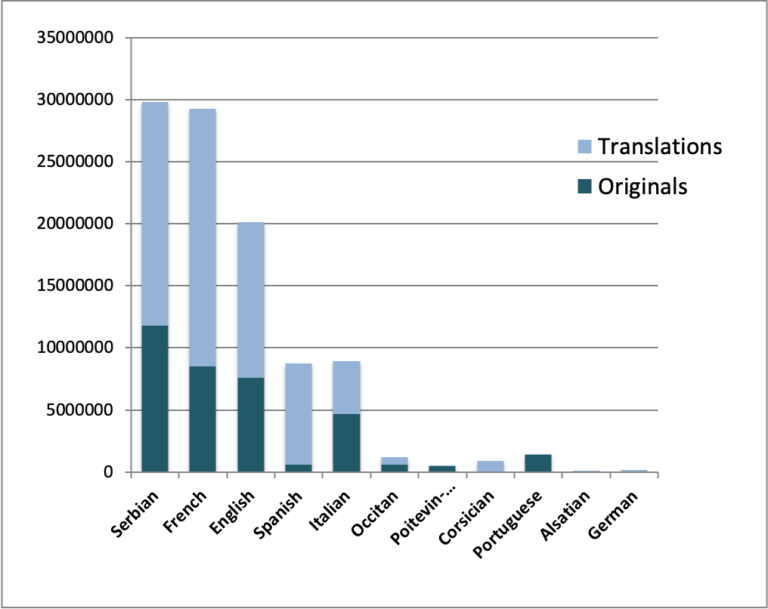
The content is predominantly literary, with texts originally written in French, Serbian, English, Spanish, Italian, Occitan, Corsican, Alsatian, Poitevin-Saintongeais, Portuguese, German and Russian, but diversification efforts are ongoing, especially towards including legal texts, subtitles and web content. In ParCoLab you can also find various journalistic and philosophical texts.
In addition to texts that are in the public domain or for which the rights for use in ParCoLab have been obtained, the corpus includes certain content protected by intellectual property rights. In accordance with Directive 2019/790 of the European Parliament and the Council of 17 April 2019 on copyright and related rights in the Digital Single Market, amending Directives 96/9/EC and 2001/29/EC, and Article L122-5 of the French Intellectual Property Code, these texts are exclusively used for the purpose of conducting text and data mining activities for scientific research. Necessary measures are implemented to ensure the security and integrity of the database where the texts are hosted. These texts, all in XML format, are not distributed, downloaded, or fully accessed. Only brief quotations are displayed randomly in search results.